In this post, I'm going to address some of the more common myths about NTP and how to avoid the mistakes which they produce. Some of these myths are grounded in fact, and in many cases it's fine to accept them if you don't need highly accurate time and you know the consequences, but they are usually based on misconceptions about how NTP works which can lead to greater errors later.
Advance warning: This is a long post! It has been brewing for a while and has ended up being quite lengthy due to the amount of data I've collected and the number of references for and against each myth.
Myth: Using the local clock is good enough
Good enough for what? Good enough for keeping 3-4 machines at roughly the same time? Possibly. Good enough for keeping within, say, 1 second of the real time for an extended period? Well, no.
As an experiment, I set up two bare metal machines. The first was configured with a number of peers, including my local LAN pool, the Australian public pool, & its own local clock (fudged to stratum 1). The second was configured with just its own local clock, also fudged to stratum 1. Both machines had an existing drift file in place from a previous experiment. I let these systems run for a few days; I then reinstalled the second system, removing the drift file.
During all this time I had a VM on the first system configured with both bare metal servers and my local stratum 1 as sources. Here's a graph of the peer offsets recorded by that VM:
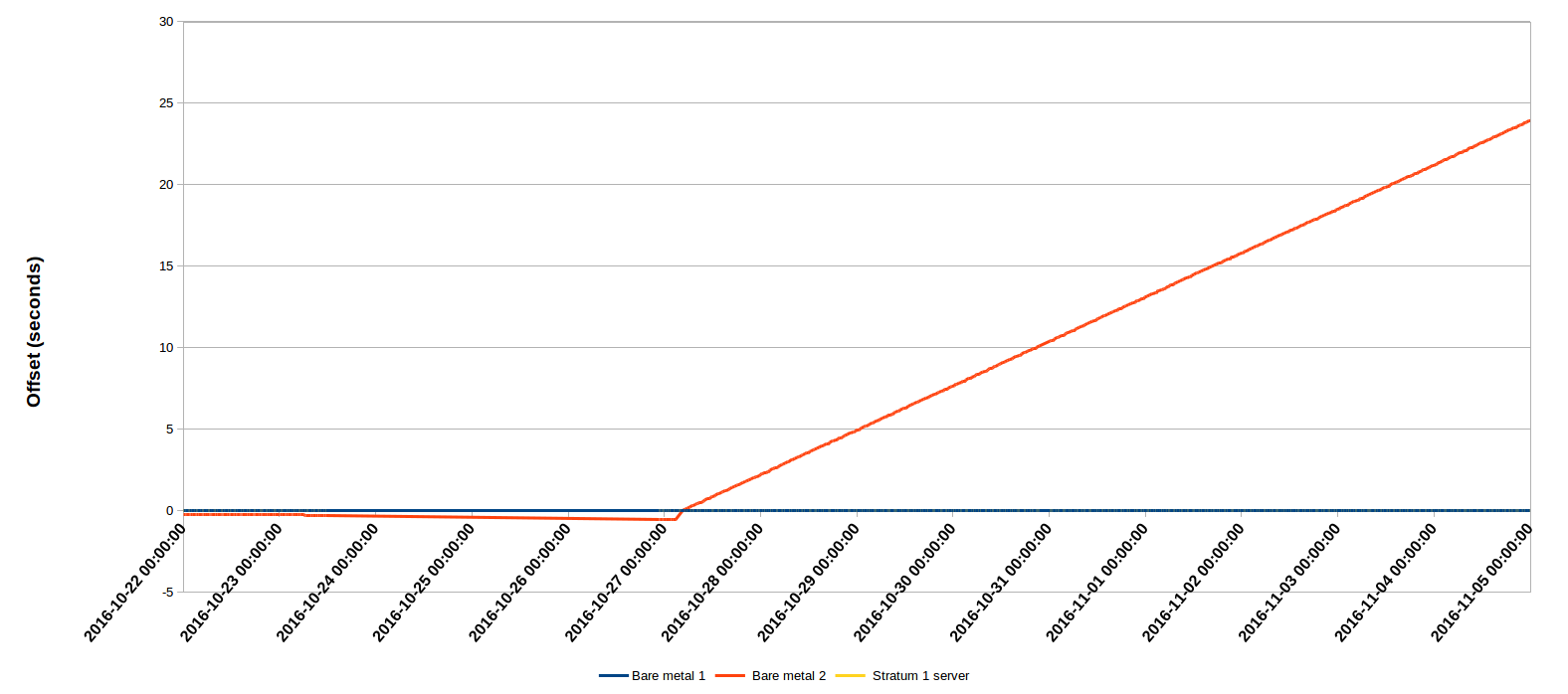
As you can see, during the first part of the experiment, the 2nd bare metal server (configured with only its own local clock) performed reasonably, only falling behind in time a little. But after the drift file was removed, it's an entirely different story. Both bare metal servers were old, cheap hardware, but the one which was configured with appropriate external sources maintained close sync with the stratum 1 source (its yellow line is hidden behind the blue line in the graph), while the one with only its local clock gained around 24 seconds in 9 days, or more than 2.5 seconds every day. That's an eternity by NTP reckoning.
Reality: You can rely on the local clock for only a very short period of time, and only when the error rate of the local clock has already been established
And even then, there are better ways to do this. NTP has orphan mode, which is a method by which a group of peered servers can agree on an interim authoritative source in the event that their connectivity to higher-stratum peers is lost for a time. In short, there is no justification for using the local clock. (Julien Goodwin's advice about local clocks was already outdated in 2011.)
Best practice: Disable the local clock and enable orphan mode
The local clock is disabled in the default configuration of most current Linux distributions. If you have an old install where you haven't updated the configuration, check it now to make sure the local clock is disabled. Comment out or delete any lines in /etc/ntp.conf beginning with server 127.127.1. or fudge 127.127.1..
To enable orphan mode, add tos orphan N to /etc/ntp.conf, where N is the stratum which the orphan server will take - 5 or 6 is usually a reasonable starting point, since servers higher than stratum 4 are rarely seen in on the public Internet. You should configure orphan mode on a group of peered servers.
Myth: You don't need NTP in VMs
This myth is relatively common in Windows/VMware environments, but can also be seen in Linux-focused materials. At its core is basically the same assumption as the local clock myth: the local (virtual) clock is good enough. So in that sense, it's not really a myth: you can get away without NTP if you're happy to have time accurate to within a second/minute/hour/whatever-your-clock-happens-to-do.
Reality: If you need NTP on bare metal, you need it in VMs
Oliver Yang's Pitfalls of TSC usage is an interesting read covering the characteristics of virtual clocks in various hypervisors. Spoiler: best case, they're no better than the oscillator in your machine; worst case, they're much worse.
I performed this experiment to demonstrate: using 8 identical VMs (running on the KVM hypervisor) running on the same Intel PC which was used in the local clock test above, I synced the time with NTP, then shut down NTP on 4 of the 8 VMs. I left them running for a few days, then measured the offset from my local stratum 1 server over a 1-day period. The host was synced using NTP throughout.
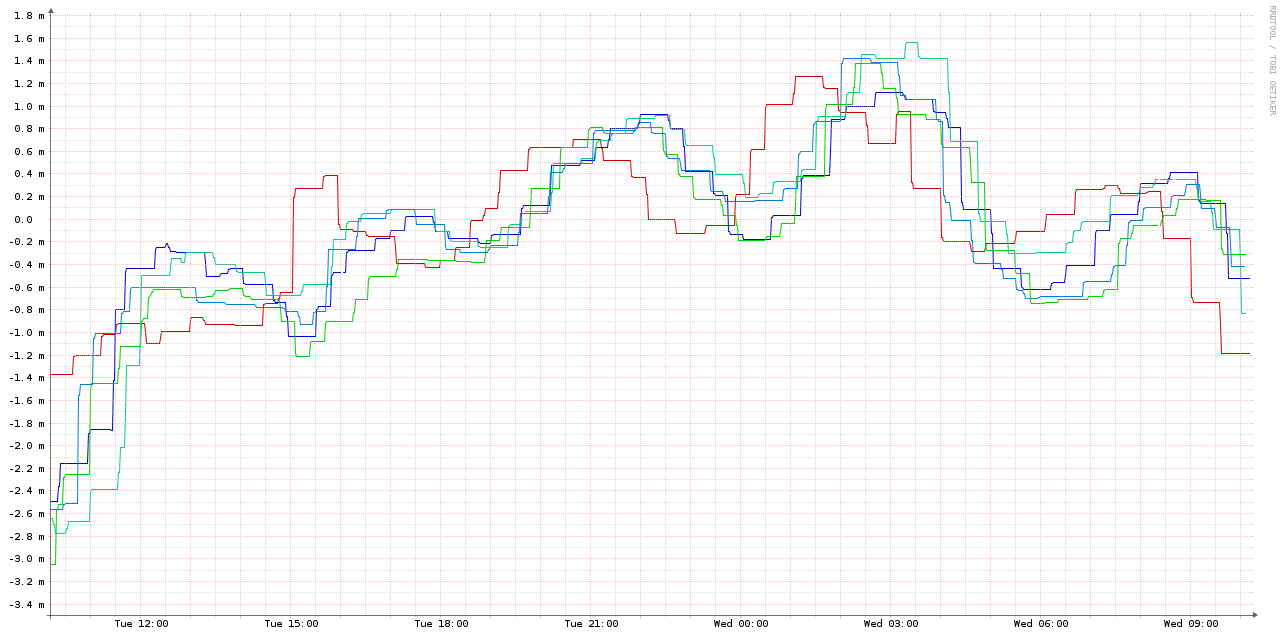
Here's a graph of the system offsets for the 4 VMs which were running NTP (the blue & green shades) and the host (red):
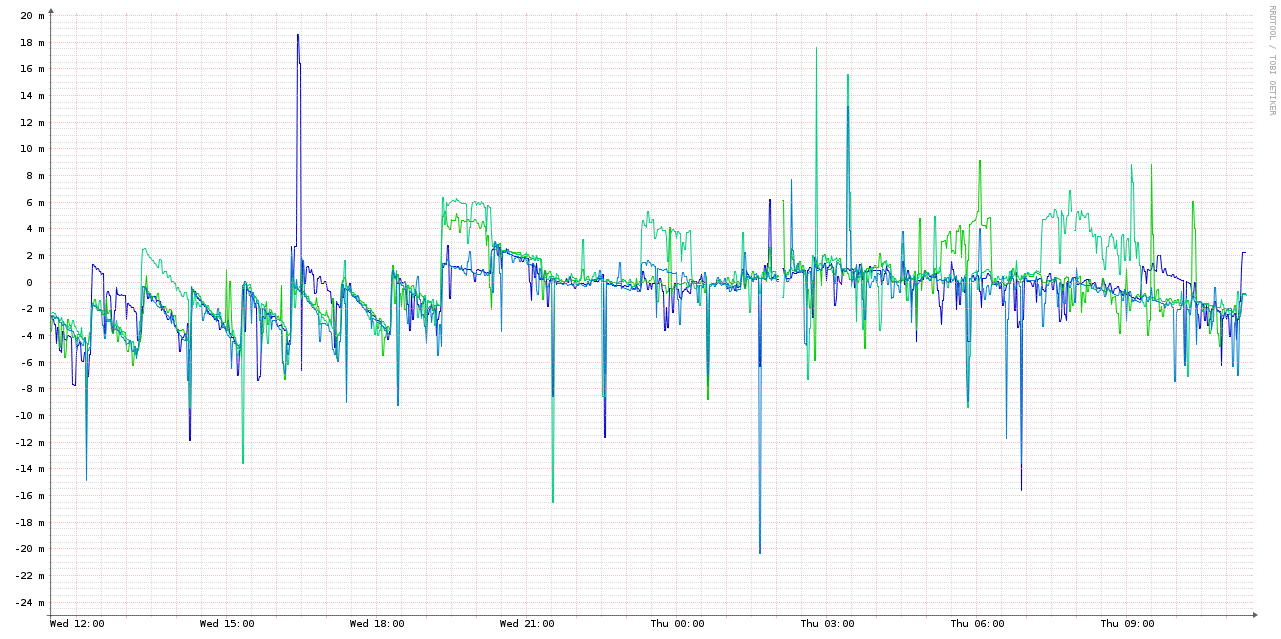
Here are the 4 VMs without NTP:

As you can see, this is two orders of magnitude worse than the ones running NTP. In case the scale wasn't obvious in the graph above, here's a combined graph - the 4 NTP-synced VMs and the host are the smudge over the X axis:

The takeaway is simple: if you want accurate time in VMs, run ntpd in them.
But, why not just sync with the host regularly?
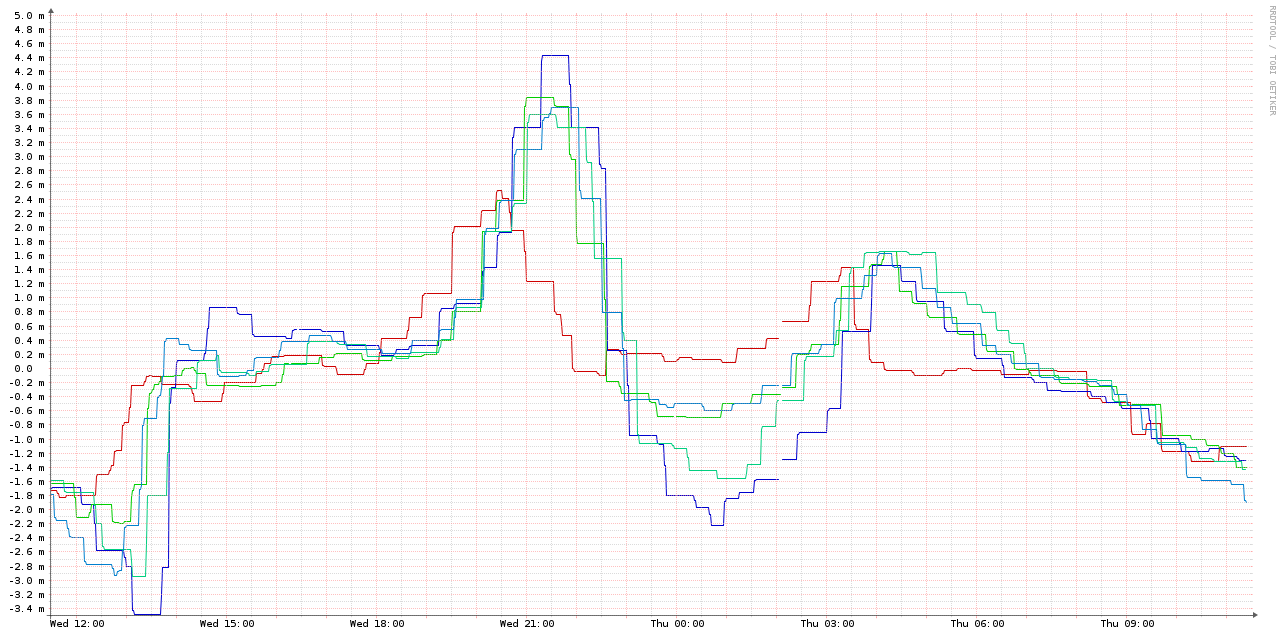
Let's try that. Here's a graph showing the same 4 VMs, with an ntpd -gq (which does a one-time set of the clock & then exits) run from /etc/cron.hourly/:
Compared to the NTP-synced VMs & the host, it's very jumpy:
Here's the combined graph with all machines, for completeness: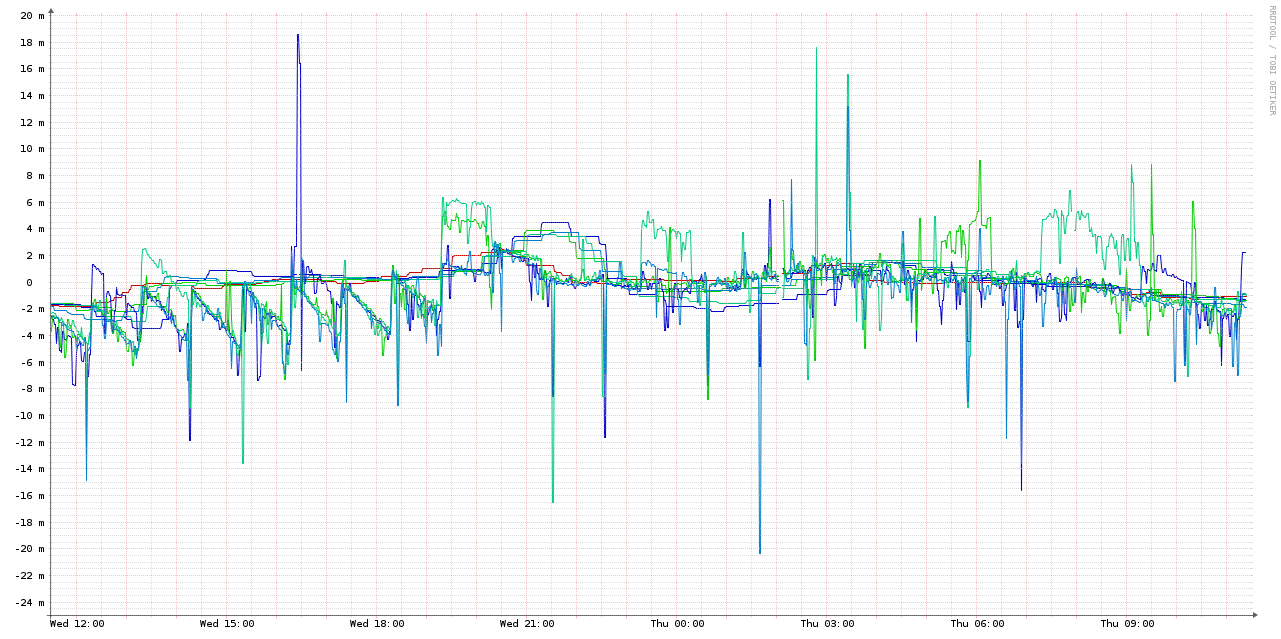
This is definitely a much-improved situation over just trusting the local virtual clock and within the tolerance of an application like Ceph (which needs < 50 ms). But in this case, the clock is stepping often, rather than slewing. That could be improved by running the sync more often, say, every 1-5 minutes, but in that case, why not just run ntpd? (For further discussion, see this Server Fault thread.)
Myth: Time sync in VMs doesn't work
This myth is firmly grounded in the ghosts of Linux kernels past. Under kernel versions up to 2.6, and early VMware, Xen, and KVM hypervisors, clocks were problematic, such that clock drivers often needed to be specified on the kernel command line. (See, for example, the VMware knowledge base article on timekeeping best practices for Linux guests, and the kernel versions mentioned.)
Reality: In most cases, VMs can maintain excellent time sync
The virtual clock drivers of modern Linux kernels are mostly adequate to support NTP (although see the article by Oliver Yang linked above for caveats).
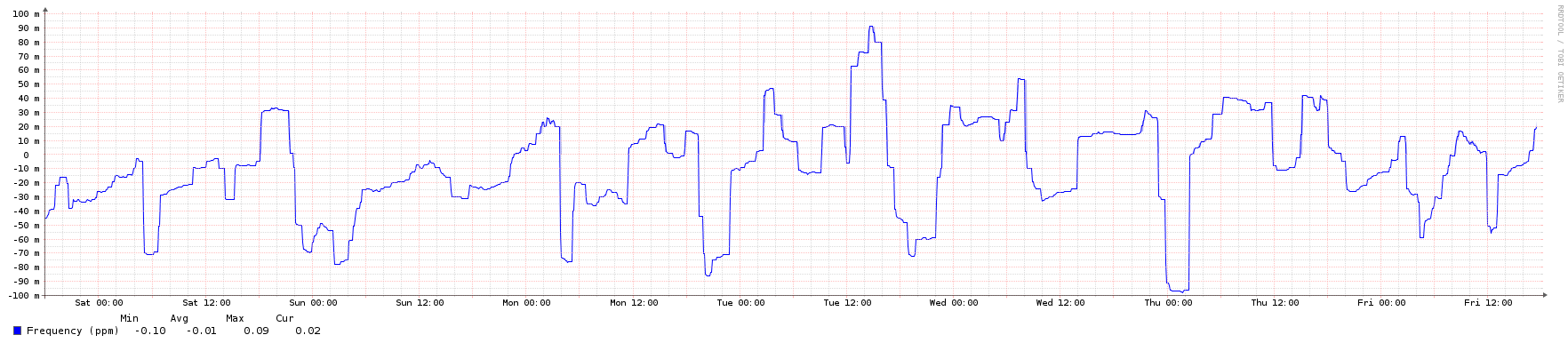
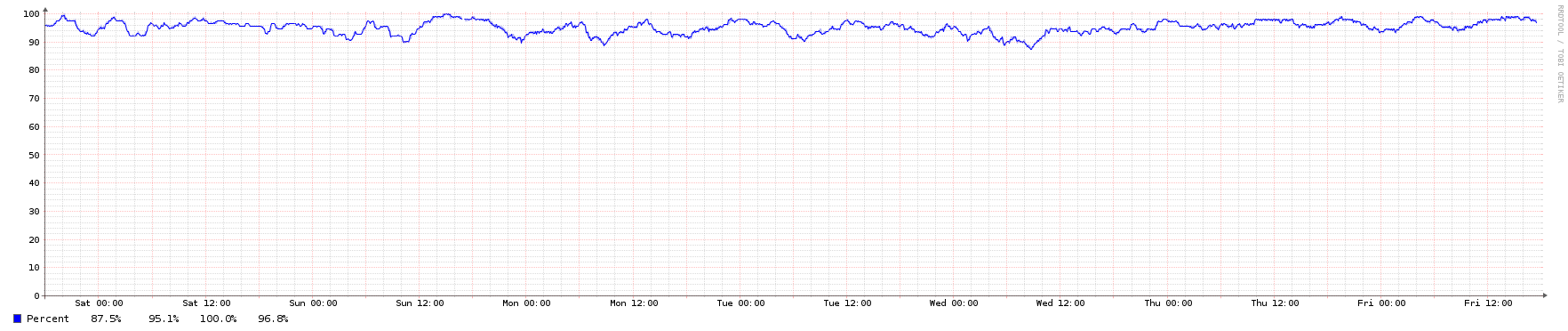
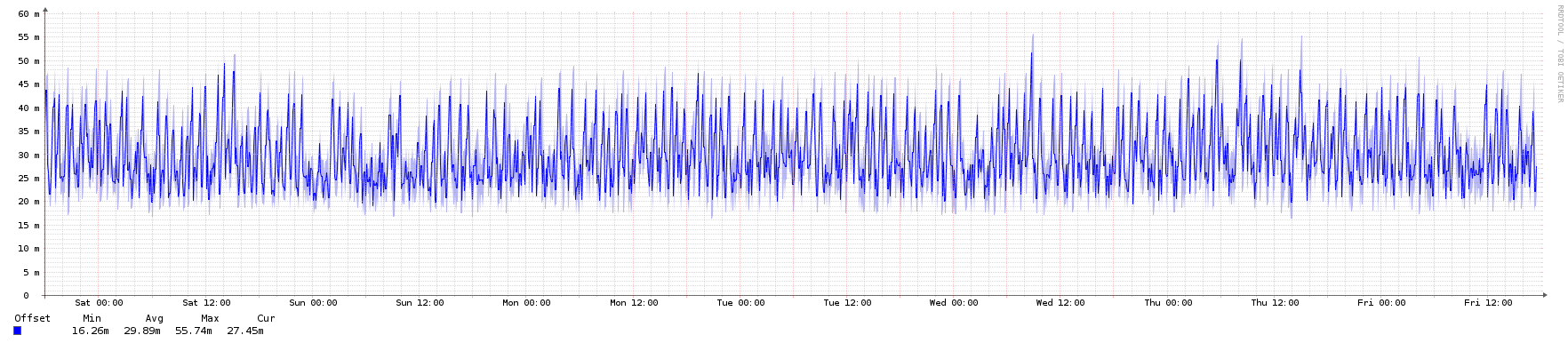
To illustrate, here are some graphs from an NTP server in the public pool over a 1-week period. It's an Ubuntu 16.04 LTS KVM instance running in an Openstack private cloud.
Frequency (error rate in parts-per-million):
Reachability of peers:
Root dispersion:
System peer offset:
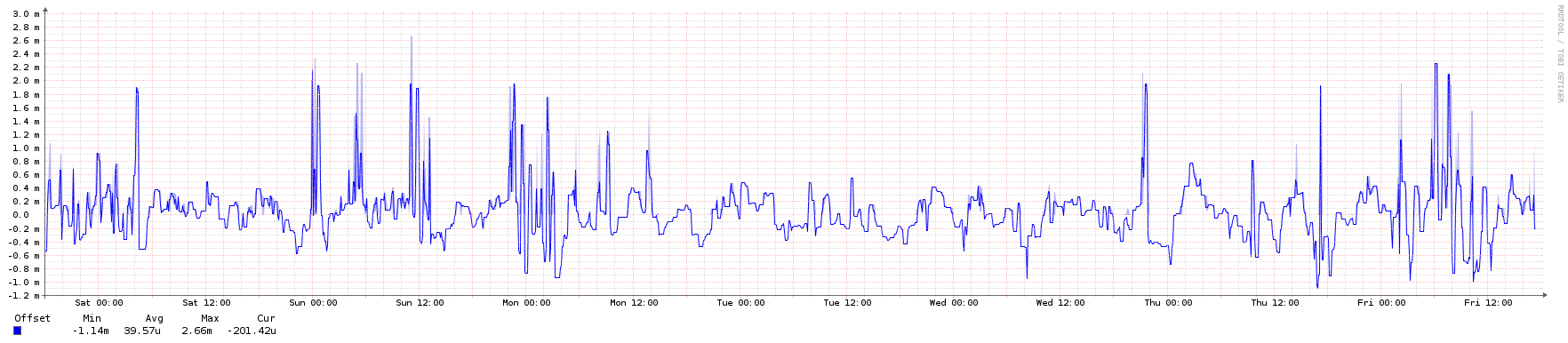
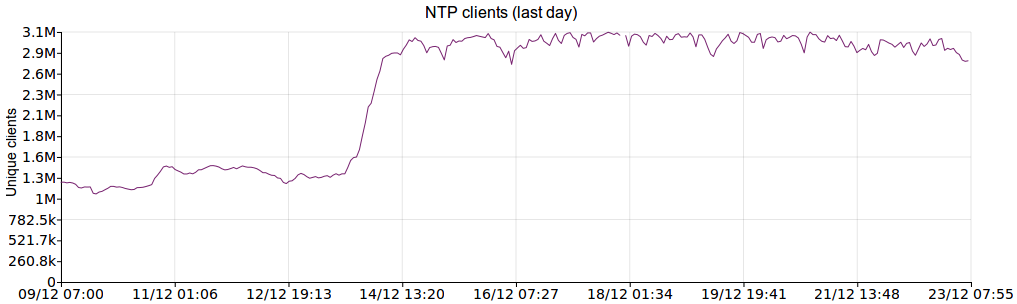
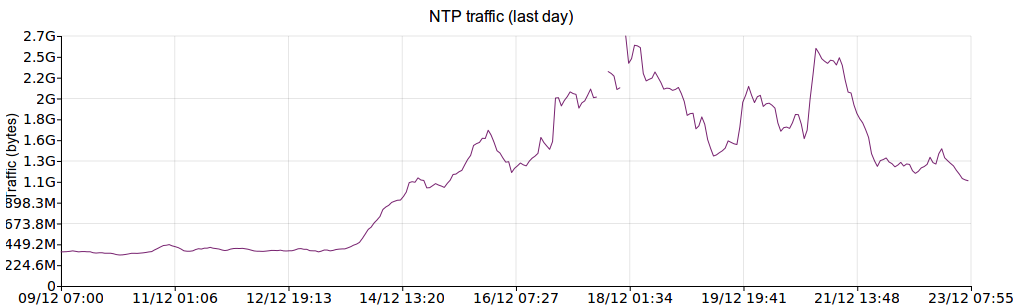
(For a recent discussion on this, see this Server Fault thread.) It should be noted that due to the Great Snapchat NTP Pool Surge of 2016 (I wish we had a snappier name for that...), this VM was under much higher load than normal, and still managed to keep good time. Here are some graphs showing a 2-week period (ending on the same date as the above graphs) which illustrate the traffic increase.
Unique clients:
Traffic transferred:
This is not a particularly powerful VM nor does it run on particularly modern hardware, and yet its pool score remains steady:
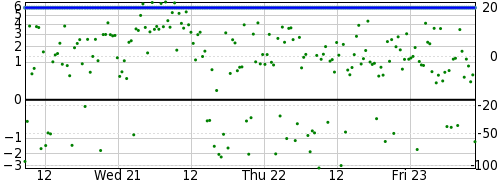
So a VM can make a perfectly viable NTP server, given the right configuration.
Myth: You don't need to be connected to the Internet to get accurate time
This is not strictly a myth, because you can get accurate time without being connected to the Internet. It is sometimes expressed something like this: "Time synchronisation is a critical service, and we can't trust random servers on the public Internet to provide it." If you work for a military or banking organisation, and expressing the myth like this is an excuse to get hardware receivers for a mix of GPS, radio, and atomic clocks, then perpetuating this myth is a good thing. :-)
But usually this is just a twist on the "local clock is fine" myth, and the person promoting this approach wants to keep misguided security restrictions without investing in any additional NTP infrastructure. In this form, it is certainly a myth. (There are circumstances where something close to this can be made to work, by having a local PPS device coupled with an occasional sync with external sources to obtain the correct second, but for the majority of use cases, the complexity and risk of running such a setup greatly outweighs any perceived security benefits.)
Reality: You need a connection to multiple stratum 1 clocks
You can use stratum 1 servers on your own local network, or you can access public servers, but ultimately you need to have a reliable external reference. The most common and affordable of the options for a local stratum 1 source is GPS (usually provided with PPS), but PPS-only devices and Caesium & Rubidium clocks are not unheard of. (See Julien Goodwin's talks for more)
(Time for a quick shout-out to Leo Bodnar Electronics, whose NTP server seems like a really nifty little box at a sensible price: if your organisation is large enough to have bare metal servers in multiple data centres, Leo's box makes it having a GPS-based stratum 1 source in each DC easy and affordable.)
Best practice: Maintain connectivity to at least four stratum 1 servers
If you maintain your own data centres or other sites and have a partial view of the sky, maintaining a stratum 1 server synced from GPS isn't difficult (especially given products like the LeoNTP server mentioned above). The NTP foundation maintains a list of stratum 1 servers, some of which allow public access. Many of the NTP pool servers (such as mine) are stratum 1 also. Or you might peer with a research organisation which has access to an atomic clock.
There is no need to connect directly to stratum 1 servers; most public pool servers are stratum 2 or 3, and as long as you have a sufficient variety of them, you'll be connected to the stratum 1 servers indirectly.
Myth: You should only have one authoritative source of time
This myth results in the most common misconfiguration of NTP: not configuring enough time sources. On first glance, and without any further information about how NTP works, it is a natural assumption that one source of time would be the master, and all other sources would stem from that.
Reinforcing this myth is a saying which crops up occasionally, known as Segal's law: "A man with a watch knows what time it is. A man with two watches is never sure." This often seems to be quoted without the knowledge that it is an ironic poke at being fully reliant on one time source.
But this is not how time (or our measurement of it, to be more precise) works, and NTP's foundational assumptions are designed to match reality: no one source of time can be trusted to be accurate. If you have 2 sources of time, they will disagree; if you have 3 sources of time, they will disagree; if you have 10 sources of time, they will still all disagree.
This is because of both the natural inaccuracies of clocks, and how the NTP polling process (described in the last post) works: network latencies between two hosts constantly vary based on system load, demand on the network, and even environmental factors. So both the sources themselves and NTP's perception of them introduce inaccuracy. However, NTP's intersection and clustering algorithms are designed to take these differences into account, and minimise their significance.
[Edit: There are some common variants to this myth, including "NTP is a consensus algorithm", and "you need more than 2 sources for NTP in order to achieve quorum". Reality #1: NTP is not a consensus algorithm in the vein of Raft or Paxos; the only use of true consensus algorithms in NTP is electing a parent in orphan mode when upstream connectivity is broken, and in deciding whether to honour leap second bits. Reality #2: There is no quorum, which means there's nothing magical about using an odd number of servers, or needing a third source as a tie-break when two sources disagree. When you think about it for a minute, it makes sense that NTP is different: consensus algorithms are appropriate if you're trying to agree on something like a value in a NoSQL database or which database server is the master, but in the time it would take a cluster of NTP servers to agree on a value for the current time, its value would have changed!]
Reality: the NTP algorithms work best when they have multiple sources
If the description of the intersection algorithm in the previous post wasn't enough to convince you that you need more than one source, here's another experiment I performed: I used the same 2 bare metal hosts which I used in the previously-described experiment, each using a single local (well-configured) source. I then configured 8 VMs on the 2 bare metal hosts: 4 used only their local bare metal server as a source, while the other 4 used my local LAN pool.
All of the VMs kept good time. Those which were hosted on the Intel Core 2 host had error rates which almost exactly mirrored their host's. This seems to be because of the constant_tsc support on the Intel platform; my AMD CPU lacks this feature. Those VMs which were hosted on the AMD Athlon 64 X2 host actually had substantially better error rates than their host; I still don't have an explanation for this.
All of the VMs maintained offsets below 100 microseconds from their peers, and the ones with only a single peer actually maintained a lower average offset from their peer than those with multiple peers. However, the VMs with multiple peers were lower in root delay by between 4 and 9%, and had a 77 to 79% lower root dispersion. (The root dispersion represents the largest likely discrepancy between the local clock and the root servers, and so is the best metric for overall clock synchronisation with UTC.) My current explanation of the lower root delay and dispersion (despite higher average and system peer offsets) is that the intersection and clustering algorithms were able to correct for outlying time samples. For full figures, see the table below.
Metric | Hosts | AMD Athlon 64 X2 | Intel Core 2 Duo |
|---|---|---|---|
Frequency (ppm) | Host | −11.5 | −31.37 |
Single-peer VMs | 0.00 | 31.39 | |
Multi-peer VMs | 0.01 | 31.4 | |
Average peer
offset (seconds)
| Host | −8.57μ | −14.77μ |
Single-peer VMs | 2.88μ | 34.5μ | |
Multi-peer VMs | 75.17μ | 28.66μ | |
Root delay
(seconds)
| Host | 1.07m | 0.97m |
Single-peer VMs | 1.4m | 1.11m | |
Multi-peer VMs | 1.28m | 1.06m | |
Root dispersion
(seconds)
| Host | 36.34m | 35.1m |
Single-peer VMs | 65.5m | 62.05m | |
Multi-peer VMs | 36.5m | 34.97m | |
System peer
offset (seconds)
| Host | -15.7μ | -42.07μ |
Single-peer VMs | 3.02μ | 18.29μ | |
Multi-peer VMs | 9.78μ | 37.92μ |
(All of the averaged figures above use absolute value.)
Best practice: configure at least 4, and up to 10, sources
I've heard plenty of incorrect advice about this (including even Julien Goodwin's 2011 and 2014 talks), which states that if you have too many time sources, NTP's algorithms don't act appropriately. I don't really understand why this belief persists, because all of the data I've collected suggests that the more time sources you give your local NTP server, the better it performs (up to the documented limit of 10 - however, even that is an arbitrary figure). My best guess is that older versions of the NTP reference implementation were buggy in this respect.
The one circumstance I have seen where too many sources caused problems is when symmetric mode was used between a large number of peers (around 25-30), and these peers started to prefer one another over their lower-stratum sources. I was never able to reproduce the issue after reducing the amount of same-stratum peering.
Myth: you can't get accurate time behind asymmetric links like ADSL
(This one comes from Julien Goodwin's talk as well.)
That depends; define "accurate". Can you get < 1ms offset? Probably not. But you can get pretty close; certainly less than 5 ms on average sustained over a long period, with a standard deviation around the same range. Here's a graph from an experiment I did with 4 VMs on my home ADSL link over a 1 week period. I made no attempt to change my Internet usage, so this covers a period where my family was doing various normal Internet activities, such as watching videos, email, web browsing, and games.
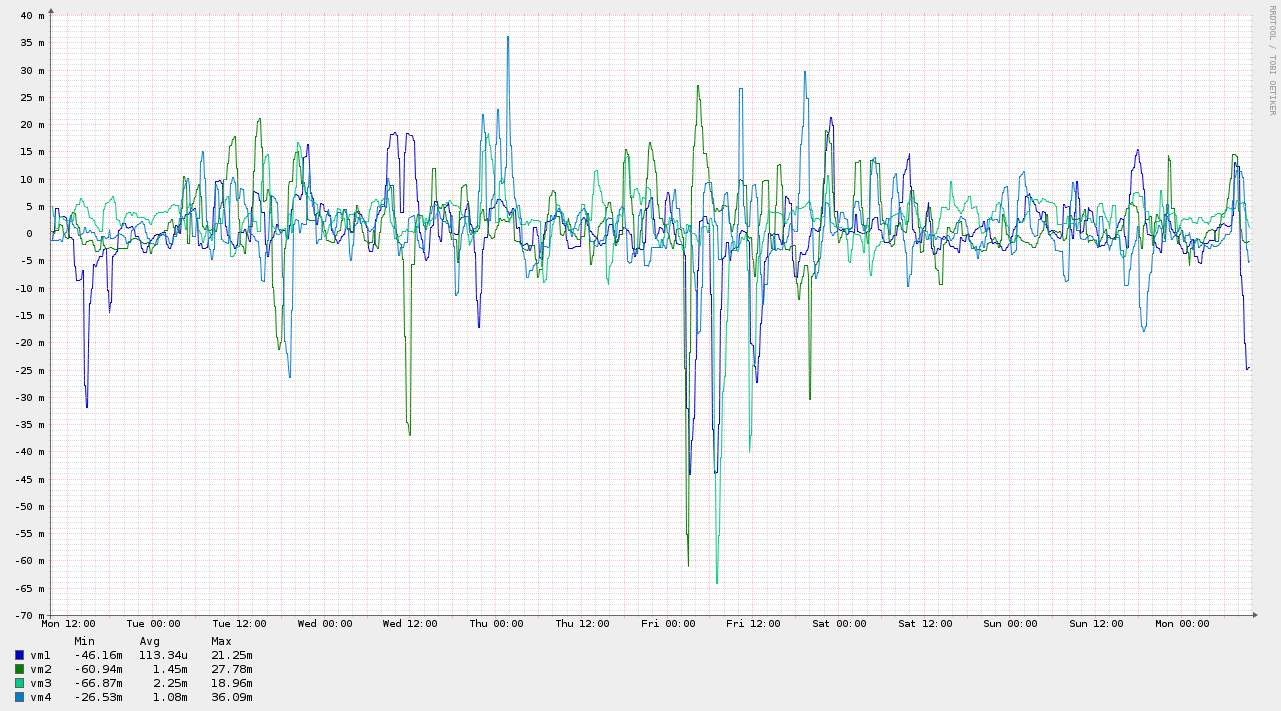
Whilst the sort of offsets seen in the diagram above are non-desirable for high-precision clients, they are certainly viable for many applications. My pool server, a Beagle Bone Black with a GPS cape (expansion board) also runs behind this ADSL link, and its pool score is rarely below 19:
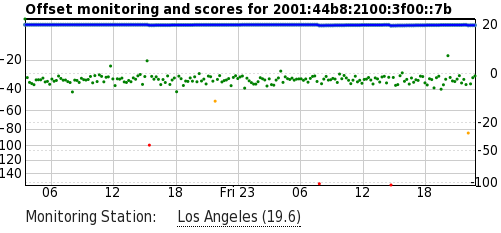
It's generally true that if you have a choice of NTP servers, you should select the ones with the lowest network delay to your location, but this is not the only relevant factor. During the the above experiment I had a number of time sources with greater than 300 ms latency, and yet they maintained reasonable offset and jitter.
NTP also has a specific directive designed to help cope with asymmetric bandwidth, called the huff-n'-puff filter. This filter compensates for variation in a link by keeping history of the delay to a source over a period (2 hours is recommended), then using that history to inform its weighting of the samples returned by that source. I've never found it necessary to use this option.
Putting it all together: sample NTP configurations
So given all of the above advice about what not to do, what should an ideal NTP setup look like? As with many things in IT (and life), the answer is "it depends". The focus of this blog series has been to increase awareness of the fundamentals of NTP so that you can make informed choices about your own configuration. Below I'll describe a few different scenarios which will hopefully be sufficiently common to allow you to settle upon a sensible configuration for your environment.
Data centres with large numbers of virtual or bare metal clients
For serving accurate time to a large number of hosts in 3 or more data centres, minimal latency is preferred, so in this scenario, a preferred configuration would be to have 4 dedicated stratum 2 servers (either VMs or bare metal - the latter are preferred) in each DC, peered with each other, and synced to a number of stratum 1 sources. (See here and here for two similar recommendations.)
Ideally, a stratum 1 GPS or atomic clock would be in each data centre, but public stratum 1 servers could be used in lieu of these, if (in the case of GPS) view of the sky is a problem or external antenna access is impractical, or atomic clocks are unaffordable.
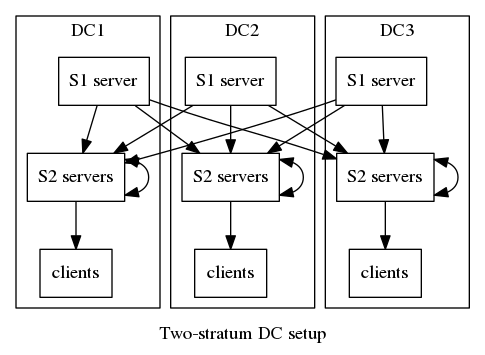
The advantages of this setup are that it minimises coupling between the clients (consumers of NTP) and the stratum 1 servers, meaning that if a stratum 1 server needs to be taken out of service or replaced, it has no operational impact on the clients.
This configuration also minimises NTP bandwidth usage between data centres (although, unless the number of clients is in the tens of millions, this is unlikely to be significant). It also ensures that latencies for the clients remain low, and makes the stratum 2 servers essentially disposable - they could be deployed with a configuration something like the following (assuming it's in DC2):
driftfile /var/lib/ntp/ntp.drift statistics loopstats peerstats clockstats filegen loopstats file loopstats type day enable filegen peerstats file peerstats type day enable filegen clockstats file clockstats type day enable restrict -4 default kod notrap nomodify nopeer noquery limited restrict -6 default kod notrap nomodify nopeer noquery limited restrict source notrap nomodify noquery restrict 127.0.0.1 restrict ::1 orphan tos 5 server ntp1.dc1.example.org iburst server ntp1.dc2.example.org iburst server ntp1.dc3.example.org iburst server public-stratum1.example.net iburst peer 0.ntp2.dc2.example.org iburst peer 1.ntp2.dc2.example.org iburst peer 2.ntp2.dc2.example.org iburst peer 3.ntp2.dc2.example.org iburst
Clients could use a configuration like this:
driftfile /var/lib/ntp/ntp.drift restrict -4 default kod notrap nomodify nopeer noquery limited restrict -6 default kod notrap nomodify nopeer noquery limited restrict source notrap nomodify noquery restrict 127.0.0.1 restrict ::1 pool 0.ntp2.dc2.example.org iburst pool 1.ntp2.dc2.example.org iburst pool 2.ntp2.dc2.example.org iburst pool 3.ntp2.dc2.example.org iburst
Any of the commonly-available Free Software automation tools could be used for deploying the stratum 2 servers and maintaining the client configurations. I've used juju & MAAS, puppet, and ansible to good effect for NTP configuration.
Distributed corporate network
A distributed corporate network is likely to have a number of (possibly smaller) data centres, along with a number of corporate/regional offices, and possibly smaller branches with local servers. In this case, you would probably start with a similar configuration to that described above for large data centres. The differences would be:
- Stratum 1 sources might be located in corporate/regional offices rather than the data centres (because getting a view of the sky sufficient to get GPS timing might be easier there), or the organisation might be entirely dependent on public servers. (For a corporation of any significant size, however, cost shouldn't be a barrier to having at least one stratum 1 server feeding from GPS in each region.)
- Bandwidth between branch offices and the central data centres might be rather limited, so corporate/regional/branch servers might be stratum 3 servers, and clients would be configured to use them rather than the DC stratum 2 servers, easing load on the corporate WAN. If their Internet bandwidth is equal to or better than their WAN bandwidth, the stratum 3 servers could also use the public NTP pool.
- To minimise configuration differences between sites, clients could be configured to use a fixed DNS name which would be directed to the local server by a DNS override (see BIND response policy zones) or a fixed IP address which is routed to a loopback interface on the stratum 3 server via anycast routing.
Standalone cloud instance
If you're using a public cloud instance and install NTP on an Ubuntu 16.04 LTS image, you'll get a default configuration which uses the NTP pool and looks something like this. In the case of the major public cloud vendors, this is a reasonable default, but with some caveats:
- Google Compute Engine runs leap-smeared time on its local time servers. Leap-smearing spreads out leap seconds over the time before & after the actual leap second, meaning that the client clocks will slew through the leap second without noticing a jump. Because they are close to the instances and reliable, Google's time servers are very likely to be selected by the intersection algorithm in favour of the pool servers. This means that your instances could track leap-smeared time rather than real time during a leap second. (I'll have more data about this in a future post - I've set up some monitoring of Google's time servers to run over the upcoming leap second interval.) Unless all of your systems (including clients) are tracking Google's time servers (which they're probably not), my recommendation is not to use Google's time servers.
- Microsoft Hyper-V seems to have a less mature virtual clock driver than KVM and Xen, meaning that time synchronisation issues on Microsoft Azure are more common, and it doesn't seem to have changed much in recent years. (I hope to have more data and possible workarounds on this in a future post as well.)
Small business/home networks
This is probably a case where accuracy requirements are low enough and the cost of setting up solid infrastructure high enough that it simply isn't worth using anything but the public NTP pool under most circumstances. If you're using a dedicated server/VM or a full-featured router for connectivity rather than a consumer xDSL/fibre gateway, it would probably be desirable to configure that device as a pool client (it will probably end up at stratum 2 or 3), and point your local clients at that as a single source.
Concluding comments
Hopefully between dispelling common myths and outlining common use cases, this post has given you enough background to help you make informed choices about your NTP infrastructure and configuration. For further (more authoritative) reading on this, see the recently-published BCP draft.
This will be the last post in this series for at least a few weeks as I focus on turning the material here into a presentable talk for the Linux.conf.au 2017 sysadmin miniconf. Hope to see you in Hobart!
Addendum: Other mistakes well worth not making
Here are a couple of other issues that cropped up as I wrote this post, but haven't found a good place to add them.
- Letting time zones confuse your thinking. NTP doesn't care about time zones. In fact, the Linux kernel (and I'd guess most other kernels) doesn't care about time zones either. There is only UTC: conversions to your local time are done in user space.
- Being a botnet enabler. NTP has been used in reflective DDoS attacks for quite some time. This seems to have gone out of vogue a little lately, and the default configuration for your distro should protect you from this, but you should still double-check that your configuration is up-to-date. The examples given above show a basic minimum set of restrictions which should prevent this.
Further reading
If you'd like to learn more about NTP, here are some suggestions:
- the earlier posts in this series (see the menu)
- try the NTP tag for more of my posts on NTP
- read the NTP Best Current Practices draft RFC
- browse the NTP project documentation
- browse NTP questions on ServerFault - you'll find me there pontificating about NTP on occasion
- check out the chrony NTP server, an alternative NTP implementation which is now the default on the Ubuntu and Red Hat Linux distributions